![[JT]](/img/jtlogo.svg)
→ Software
Flinch link checker - Documentation
Table of Contents
- 0. Introduction
- 1. Installing Flinch
- 2. Starting Flinch
- 3. Configuration
- 4. Creating a new project
- 5. Walking your site
- 6. Checking external links
- 7. Creating a HTML report
- 8. Creating email reports
- 9. Editing the project file
- 10. Cleaning the project file
- 11. Running Flinch regularly
- Appendix A. The XML files
- Appendix B. License
- Appendix C. Using Flinch on two hosts
0. Introduction
Flinch is a powerful and flexible web link checker that will make your life as a web designer or web server admin easier. It can be used to check all the external links on your web pages periodically and produce HTML reports of its findings. If a web resource at the end of a link has not been reachable for a few days, Flinch can send you an email. Flinch is implemented in Perl and released under the GPL (GNU General Public License).
1. Installing Flinch
Flinch needs the Perl modules XML::Generator, XML::Parser::PerlSAX, HTML::LinkExtor, LWP::UserAgent, URI, Digest::MD5, and HTTP::Status from CPAN. If you don't know which modules are installed on your system, it is probably easiest to just start Flinch and then install all the modules for which you get an error message.
To install Flinch you have to follow these steps:
- Clone the git repository.
- Copy the programm flinch to somewhere in your path
- The documentation is in the doc directory and consists of a HTML file and a style sheet. You can copy them anywhere, but make sure that both files are in the same directory.
- Create a directory .flinch in your HOME directory and copy the file example-config.xml into it, renaming it to config.xml. Edit the file to suite your needs.
- Create a new project as explained in chapter 4
2. Starting Flinch
Flinch is started from the command line, with the first argument specifying the task Flinch should perform. The following table shows the available tasks:
| Task | Description | See chapter |
|---|---|---|
| help | Print a short usage summary. | |
| version | Print the version number. | |
| init | Initialize a new project. | Chapter 4 |
| walk | Walk your web site to check all internal links and find all external links. | Chapter 5 |
| check | Check all (or some) external links. | Chapter 6 |
| report | Create a HTML report for a project. | Chapter 7 |
| Send mail reporting broken links. | Chapter 8 | |
| edit | Starts an editor on the project file. | Chapter 9 |
| clean | Clean history entries from project file. | Chapter 10 |
| info | Read the config files and do nothing else. Used for debugging. | |
| recycle | Read the config files and write the project file back. Used for debugging. |
For the version and help task, no other arguments are needed on the command line. For all other tasks a project name must be specified. In addition, some options can be given on the command line. Some tasks have special options, but the following options are interpreted by most tasks:
| Long/short option | Description |
|---|---|
| --configdir=dir, -c dir | Configuration directory that should be used instead of ~/.flinch. |
| --time=hours, -t hours | Only run the task if the last run is more than time hours ago. |
| --verbose, -v | Print verbose messages while doing the work. |
3. Configuration
All the configuration for Flinch is read from XML files. Flinch will look for these files in in the ~/.flinch directory by default. You can change the directory with the --configdir (or -c) option.
The main config file is called config.xml. Every set of web pages that you want Flinch to check is called a project and each projects configuration is stored in a project file, named PROJECT-NAME.xml in the same directory.
The project file is more than a config file: When Flinch is running the walk and check tasks, it will add all the information gathered to the project file. In addition, Flinch will note the last time it ran the walk, check, report and mail task to the file.
The main config file will only be read and never written to by Flinch.
The main config and the project XML files can be edited at any time. Subsequent runs of the program will read the changed information and act accordingly.
Here is a complete list of all available configuration settings in alphabetical order:
| Element | Default | Description | Which XML file? |
|---|---|---|---|
| The mail address where reports should be sent. | config/project | ||
| emailfrom | flinch@HOSTNAME | The mail address used as sender for email reports. | config/project |
| prefix | This is something like http://www.example.com/ or http://www.example.org/~foo/bar. All web pages with this prefix will be recognized as local pages. All other web pages are external. | project | |
| project | This is the id of the project. | project | |
| reportdir | The directory where HTML reports are written. This can include the special string '%p' which will be replaced by the project name. Example: /var/www/flinch/%p | config/project | |
| reportprefix | If this is set all local URLs in a report will have this prefix instead of the one set with prefix. Have a look at Appendix C to see why this might be useful. | config/project | |
| reporturl | This is the URL corresponding to the reportdir directory. It can include the special string '%p' which will be replaced by the project name. Example: http://localhost/flinch/%p | config/project | |
| schemes | http ftp | A space separated list of allowed URI schemes. Only resources with URIs in one of these schemes are checked. Generally, the default is what you want. | config/project |
| startpath | This must be given relative to the prefix. It is the URL where Flinch should start crawling your web site to check all internal links and get the list of all external links. An example would be /index.html which would make the whole URL http://www.example.org/~foo/bar/index.html if the prefix was set to http://www.example.org/~foo/bar/. | project | |
| stylesheet | flinch-style.css | The path to the style sheet. This is used as is from all the report files. Make sure you have a style sheet at that URI. | config/project |
| timeout | 30 | The timeout used when getting resources over the network. (In seconds.) | config/project |
| useragent | Flinch/VERSION | The content of the HTTP User-Agent Header used. | config/project |
| warn | 3d | This is the warn interval after which broken links are reported. This value is only used by the mail task, not by the report task. The format used is a list of numbers and interval IDs like this: '4w3d5h3m2s' (4 weeks, 3 days, 6 hours, 3 minutes and 2 seconds). | config/project |
4. Creating a new project
To create a new project call Flinch with the init task:
$ flinch init project-name
Flinch will then ask you a few questions about the new project. The answers to these questions will be written into a new project file named PROJECT-NAME.xml in the Flinch directory.
Flinch needs at least the following information to create a new project:
- The project name
- If the project name was not given on the command line, Flinch will ask for it. The project name can only consist of lower case letters, numbers, the underscore and the hyphen. This will be stored in the project config variable.
- The prefix for all your web pages
- This is something like http://www.example.com/ or http://www.example.org/~foo/bar. All web pages with this prefix will be recognized as local pages. All other web pages are external. This will be stored in the prefix config variable.
- The start URL
- This must be given relative to the prefix. It is the URL where Flinch should start crawling your web site to check all internal links and get the list of all external links. An example would be /index.html which would make the whole URL http://www.example.org/~foo/bar/index.html. This will be stored in the starturl config variable.
- Directory for the HTML report
- This is where all HTML report files will be stored. This directory must exist. Example: /var/www/flinch/foo. This will be stored in the reportdir config variable.
- URL for the HTML report directory
- This is the URL corresponding to the directory named in the last step. Example: http://localhost/flinch/foo. This will be stored in the reporturl config variable.
- Your email address
- Your email address is needed to send you reports. This will be stored in the email config variable.
Flinch will offer a default value for some options. Just press RETURN if you want to accept the default.
All the other configuration data will use defaults unless you change the projects XML file to say different.
The last step in creating a new project is copying the flinch-style.css CSS style sheet file into the report directory. Otherwise the reports will look quite bland.
5. Walking your site
After setting up a new project the next step is to crawl your site to find all your HTML pages and check all internal links. This can be done with
$ flinch walk project-name
You can and should repeat this step whenever your web pages change.
Flinch will report immediately if you have some internal broken links, but it will not check external links at this step. External links are only recorded in the project file. If you create your web pages offline, on a notebook computer for instance, you can still run this step, because no external pages will be accessed.
By default Flinch will check all internal links, i.e. it will get all internal web pages, images, style sheets, etc. All resources of type 'text/html' will be checked for internal links and these links will be followed. You can use the <skip> element in the project XML file to modify this behaviour on a URL-by-URL-basis. See the chapter on project configuration.
Note that Flinch does not respect a robots.txt file on the site you are crawling, because, as a rule, the robots.txt file is designed to protect you from foreign robots, not necessarily from your own. Flinch is designed for use on your own site, where you hopefully know what you are doing. Use the <skip> element in the projects file, if you want to block parts of your site like CGIs or other dynamic content. Don't crawl foreign sites with Flinch without the permission of the owner!
If Flinch is interrupted by a signal while walking your site, the project XML file is not written.
6. Checking external links
After crawling your site, and periodically thereafter, you should check all external links by calling Flinch as follows:
$ flinch check project-name
When called with the check task, Flinch will loop over all external links and try to get the named resources. With the following options you can restrict which links should be checked.
| Long/short option | Description |
|---|---|
| --head, -h | Force usage of HEAD request, even if a HEAD request failed before. If you started a check when your Internet connection was down and all checks failed, all links will be marked "don't try a HEAD request next time". This option will clear this condition. |
| --level=level, -l level | Only check links in one of the levels given. Possible values are 'unchecked', 'ok', 'warn', 'error' or a comma separated list of these. |
| --state=state, -s state | Comma separated list of states. Only check links in one of the states given. For a list of possible values see the chapter on creating HTML reports. |
| --url=URL, -u URL | Only check URLs matching this pattern. |
For instance,
$ flinch check -l error project-name
will only check links that had some error the last time they were checked.
The result of the check will be written to a <result> element in the project XML file. Various information, like the time the check was performed, the HTTP return code, etc. will be stored in the attributes of the <result> element.
Together, all the <result> elements for a link make up its history. The history is kept in the XML file. By default the history is only kept back to the last time a positive response was received. This can be changed with the keep attribute to the <history> element.
Each check will first be tried with the HEAD method. If the check fails, a GET request will be used. Unfortunately many servers return bogus error messages when the HEAD method is used, so we have to try GET. Flinch will keep track of all servers where the HEAD request failed and use a GET request directly the next time the link is checked.
If Flinch is interrupted by a signal while checking the external links, the project XML file is written with the current status, i.e. some of the links will have a new check entry and some don't. If a SIGHUP is received, the current state is written to the project XML file and the checking continues. Note that it might take a moment for the signal to register, because a currently running check of a link is not interrupted.
7. Creating a HTML report

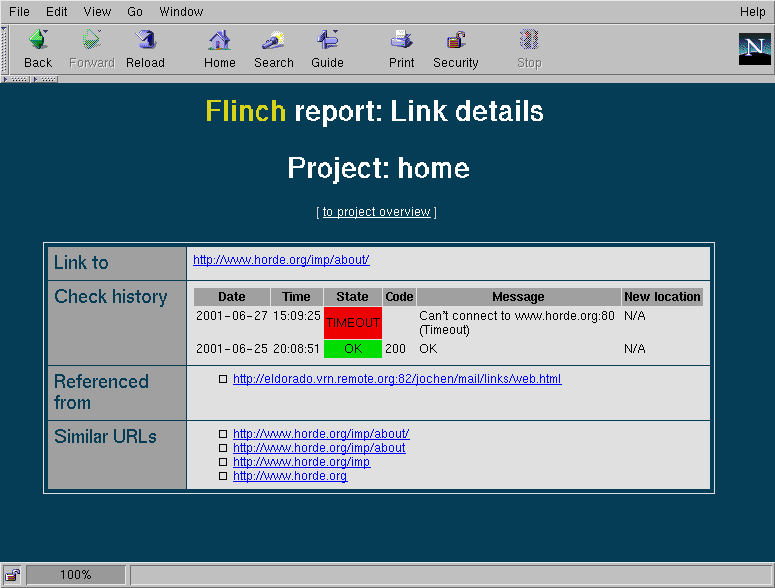
To create a HTML report from the current state of the XML file, use the report task. The report consists of an overview page and, for every external link, a page with all the details. If the option --short is used, a short report will be generated containing only links not in the 'ok' state.
The overview will show a list of all external links, the date the last check for this links was performed, the result of that check, the URL and a Details link to open the detailed information for this link.
Here is a list of states a link can be in:
| State | Description | HTTP return code |
|---|---|---|
| FORBIDDEN | You don't have permission to get this resource. You should fix the link immediately. | 403 |
| NOT AUTH | You don't have permission to get this resource. You should fix the link immediately. | 401 |
| NOT FOUND | The resource was not found. You should fix the link immediately. | 404 |
| TIMEOUT | A timeout occurred while getting the resource. This is probably a temporary error. Some other errors like 'no route to host' will also be reported as a TIMEOUT. | 503, 504, ... |
| EMPTY | The resource is empty. You should fix the link immediately. | 204 |
| DNS | A DNS lookup failed. | N/A |
| ERROR | Some other error occurred. Check the information on the details page. | 4xx, 5xx |
| UNKNOWN | Something, for which the application was not prepared, happened. This is probably a bug in Flinch. Please report this to the author. | N/A |
| MULTI | There are multiple resources behind this link. | 300 |
| MOVED | The resource has moved permanently. The link should be updated. | 301, 410 |
| REDIRECT | The resource has moved temporarily. You have to check this manually. Sometimes it is perfectly normal, for instance some web sites make up a session id on the fly and send you a redirect with this session id. Sometimes the page really has moved and you should fix it. | 302 |
| HTTP | This link is ok. This is an http link and the corresponding https ressource also exists. This can help you with finding links on your site you want to upgrade to https. | 200 |
| OK | This link is ok. | 200 |
| UNCHECKED | This link hasn't been checked yet. | N/A |
The Link details page will show the following information:
- The checked URL
- A history of recent check results for this URL
- The time this URL was last modified
- A list of links to all the pages on your site with a link to the checked URL
- A list of similar URLs to the one that was checked. This list is automatically generated using some simple heuristics. If a URL has moved, it is often useful to try these URLs to find the new URL.
The check history will contain the following information:
- The date and time of the check
- The duration of the request
- The result of this check
- The HTTP response code (if available)
- A text message explaining what happened
- The new URL of the resource (if it has moved)
If Flinch is interrupted by a signal while writing the report the report will be incomplete.
| Long/short option | Description |
|---|---|
| --short, -s | Generate short report. 'OK' links are not included. |
8. Creating email reports
Using the mail task, flinch can send emails telling you about broken links. Call flinch as follows.
$ flinch mail project-name
This will only send you email if there is anything to report. Use the --force option if you want to get an email in any case.
| Long/short option | Description |
|---|---|
| --force, -f | Send a mail even if there is nothing to report. |
9. Editing the project file
You can edit the project XML file whenever you want. Changes will be reflected the next time you run Flinch. To make your life a little bit easier, you can call Flinch as follows to edit a projects file:
$ flinch edit project-name
This will open an editor and load the project file into it. Flinch will use the content of the XMLEDITOR or, if not found, the content of the EDITOR environment variable to decide which editor to start. If both variables are not set, vi will be started.
10. Cleaning the project file
If a link isn't reachable for a long time, more and more history entries for the link will accumulate in the project file. To clean this up call:
$ flinch clean project-name
This will remove all history entries from all links except the first and last one. This way you can still see when the first failure happened and when the link was last checked.
See also the keep attribute on the history XML element in the project file.
11. Running Flinch regularly
Most people want to run the check and mail tasks regularly and automatically by cron. On the other hand, cron might be too regular - you might just hit a web site's maintenance interval every day and thus get the impression that the page is "always down" when in fact it is only down for five minutes a day. To work around this, you can use the --time option of Flinch:
Call Flinch every hour from cron, but use e.g. --time=21 to request it run every 21 hours. Flinch will be started every hour, but if less than 21 hours have elapsed since it last ran it will quit immediately. The effect is, that the real check time will be different every day.
The walk task should be run whenever your web pages change. The report task can either be run regularly after the check task or whenever you want to have a look at the HTML report.
Appendix A. The XML files
For some "advanced" configuration you have to edit the XML files. This is not as difficult as it might seem, as the file format is mostly self-explanatory. This appendix will explain the details.
The is a DTD (flinch.dtd) included in the distribution, but Flinch currently does not use a validating parser.
The XML config and project files have a similar layout. Both use the same DTD (flinch.dtd) and have <flinch> as the root element. Here is the general layout:
The <config> section appears in both the main config file and the project files. All other sections can only exist in the project files. The <skip> and the <link> elements can be repeated as often as needed.
A.1 The <config> element
Both the config.xml and the project files contain a <config> section. The config.xml file sets the defaults for some config variables, the project files can overwrite settings and add new ones.
The <config> section generally looks like this:
See the configuration section for a list of config elements.
A.2 The <last> element
Flinch uses the <last> element to store the times it last ran the walk, check, report and mail tasks. This is needed for the --time option to work. The time is given in seconds since the epoch (1970-01-01 00:00:00 UTC). The element looks like this:
A.3 The <skip> element
<skip> elements can be used to restrict which pages Flinch will access. The type attribute ('prefix', 'suffix', 'regex', 'url') together with the content of the <skip> element specifies which URLs should be excluded. If the 'suffix' attribute is used, everything after an optional '?' in the URL is ignored.
The action attribute specifies which action to take if the URL matches. An action of ignore means not to get the resource. nofollow means that the resource should be checked, but links on the page should not be followed. nofollow is the default.
A few examples:
A.3 The <link> element
For each external link that Flinch encountered in the walk phase, there is a <link> element in the project file. The to attribute contains the URL of the link's destination. For every local URL that has a link to the external URL, there is a <ref> element. The responses to the last checks are stored in the <history> elements described in the next section.
A.4 The <history> element
The <history> element and its sub-elements are used to save the responses to the last checks. By default all responses up to the last successful response will be stored. The keep attribute of the <history> element can be used to configure a maximum number of responses to keep. Setting this to "0" or not setting it at all will result in the default behaviour.
Here is an example history section:
Here time is the time in seconds since the epoch (1970-01-01 00:00:00 UTC) when the check was performed. state is the state of this check. The HTTP response code is stored in code. The location attribute is used to store a new location for a redirect response. If there is any user readable message, it is supplied in message. The duration of the request in seconds is stored in duration. If the server supplied a Last-Modified header, the time is stored in lastmod.
Appendix B. License
Copyright © 2001-2020 by Jochen Topf <jochen@topf.org>
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307, USA
Appendix C. Using Flinch on two hosts
Some people are editing their web pages not on the web server itself, but on a different system. Only when the pages are finished they are moved to the real server. Flinch can handle this situation, because the check can be run on a different computer from the one where the report is generated.
To set this up do the following: Install Flinch on both computers. On the real web server (S) create the config files as described in Chapter 3 and 4. The reporturl and reportdir configuration options should point to the computer you do the editing on (E).
Edit the project XML file and add the config option reportprefix. It should point to the place on host E where you are testing your pages. It should similar to this:
Now copy the config.xml file to your editing host (E). Run the walk, check and mail phases on Host S. Whenever you need a report copy the project XML file from S to E and run Flinch there to generate the report. All the links in the report will point to your test pages on E, not to the real pages on S.